

Data scientist en entreprise: ses missions au quotidien
Mar 11, 2025Dans un article précédent nous avions présenté la data science et donné des exemples d’application dans le monde réel. Sous l'impulsion du Big Data, les entreprises recherchent des data scientists qualifiés capables d'analyser et d'interpréter des volumes massifs de données. Que vous soyez un data analyst expérimenté cherchant à évoluer vers un rôle de data scientist ou si vous débutez dans le domaine, il est essentiel de connaître ses différentes missions en entreprise. Dans cet article nous décrirons le quotidien du data scientist en détaillant chaque étape.
Le workflow
Le travail du datascientist consiste en plusieurs étapes illustrées par le schéma ci-dessous:
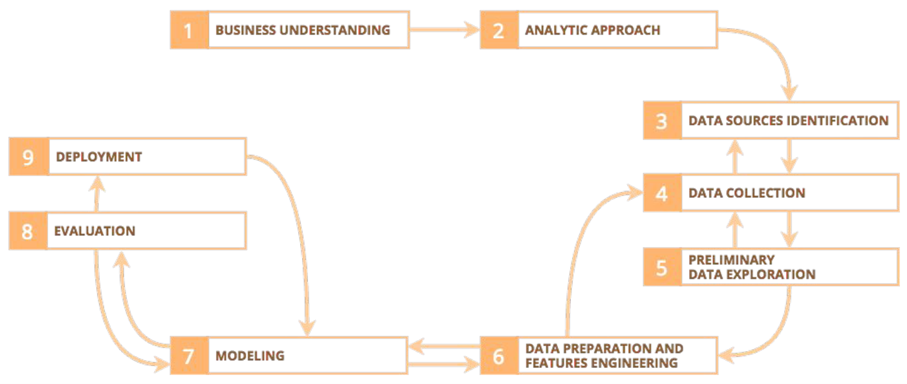
Workflow du data scientist
Le data scientist est responsable de concevoir et de développer des visualisations interactives, intégrant des modèles prédictifs. Pour mettre en place ce service, il convient de suivre les étapes itératives suivantes:
- Comprendre le métier (business understanding) : Il s’agit d’échanger avec les différents interlocuteurs métiers pour de comprendre leur activité, leur problématique et leur défis afin de trouver un cas d’usage. Cela nécessite une étroite collaboration avec les équipes métiers mais aussi avec l’équipe marketing travaillant sur des analyses statistiques.
- Avoir une approche analytique (analytic approach) : lors de cette phase le data scientist pose sa problématique : « que veut-on impacter au niveau des métiers ? » Quand il trouve la réponse à cette question il sera en mesure de définir une (ou plusieurs) variables cible que l’on souhaite prédire, au moyen de différentes variables prédictive avec lesquelles elle est corrélée.
- Identifier les sources de données (data sources identification): La source de données fait référence à l'origine ou à l'emplacement à partir duquel les données sont collectées ou obtenues à des fins d'analyse. Au cours de cette étape on devrait s’assurer de la disponibilité des données et de leur qualité en se poser des questions comme : « Existe-t-il des sources ‘open data’ ? » ou « La précision des données est-elle suffisante ?» . Des enjeux politiques ou juridiques liés à la confidentialité des données entre les équipes internes ou des données clients peuvent constituer un frein dans la mesure où il faut passer par des étapes supplémentaires comme l’anonymisation de certaines valeurs/libellés.
- Collecter les données (data collection): en fonction des types de sources de données identifiées (base de données, fichiers plats) la récupération de données peut poser des problématiques liées aux technologies à utiliser pour les extraire. Par exemple en cas de fichier plats volumineux il faudra utiliser les technologies adaptées pour charger les données et les manipuler. Si la donnée est présente dans un data lake il faudra maitriser les outils permettant de l'extraire. Avoir une bonne connaissance du marché BI sera un atout à cette étape.
- Explorer les données (preliminary data exploration): c’est-à-dire analyser le dataset afin de mieux comprendre la nature des données. A la manière d’un détective qui fait attention aux détails, une inspection minutieuse des données est réalisée pour découvrir ses caractéristiques avec des métriques statistiques par exemple, ses tendances et problèmes potentiels. Des visuels tels que les histogrammes et les boîtes à moustache peuvent être utilisés dès cette étape pour représenter statistiquement le jeu de données.
- Préparer la données (data preparation / preprocessing) : en constituant un dataset de qualité homogène avec une structure et des formats cohérents. Grâce à ces transformations, il ne sera plus simple d’identifier les liens de corrélation des variables et donc de créer un modèle prédectif. Quelques exemples de tâche à réaliser à ce niveau :
- Nettoyer (Cleaning) les données comme gérer les valeurs absentes/nulles ou dites aberrantes (outliers)
- Mise à l’échelle (Scaling) destiné à réduire le « poids » des valeurs de certaines colonnes. Habituellement on utilise un échelle en 0 et 1 pour éviter que de grands intervalles perturbent les plus petits.
- Croisement des données initiales avec les autres sources comme par exemple une base de données transactionnelle avec les logs d’un site web.
- Créer un modèle prédictif: il s'agit de comprendre les phénomènes observés dans un jeux de données (data set) afin de choisir le(s) algorithme(s) de machine learning qui correspondent le mieux aux corrélations des observations passées. On parle alors de machine learning qui représente l'ensemble des outils statistiques et informatiques permettant de construire un modèle prédictif à partir d'un ensemble d'observation. Chaque observation passée d'un phénomène, comme par exemple : "Mr Martin a été promu directeur commercial de l'entreprise avec telles conditions / avantages", est décrite au moyen de deux types de variables:
- Les variables prédictives, qui représente les informations à disposition comme l'âge, le salaire ou encore l'historique des bilans annuels de la performance en entreprise. Pour chaque observation elles sont représentées sous la forme d'un vecteur x = (x1, x2, … , xp) à p composantes.
- La variable cible notée y dont on souhaite prédire la valeur pour des événements non encore observés. Dans notre exemple: "quelle est le bénéfice ou la perte estimée pour l'entreprise suite à la promotion d'un salarié". Cette variable est aussi représentée sous la forme d'un vecteur.
- Evaluer le modèle: afin de vérifier la performance du modèle, le data scientist devra choisir des métriques pour mesurer les erreurs commises et éviter de tomber dans certains pièges comme le surapprentissage (overfitting): lorsque le modèle fonctionne bien sur le jeu de donnée dont on connait déjà les résultats (la valeur de la variable cible) mais pas pour les "nouvelles" observations. Pour contrôler cette tendance, il pourra répartir les données en deux groupes séparés: 80% pour l'apprentissage et 20% pour le test afin de vérifier que l'algorithme soit capable de généraliser les liens entre les observations et les résultats à de "nouvelles" observations. Il choisira ces métriques en fonction du type d'algorithme utilisé (régression, classification …), de la nature de la variable cible (continue ou discrète) ou encore de la sensibilité des valeurs dites aberrantes (outliers).
- Déployer l’application: enfin le data scientist devra s'assurer que son programme de machine learning supporte le passage en production avec le traitement de données plus volumineuses et plus variés. Il devra alors optimiser l'efficacité de son code afin d'obtenir des temps de réponse corrects. Un approche intelligente avec la suppervision d'une IA comme gemini pour la revue de code, et la délégation du travail de réécriture du code auprès d'un équipe IT amélioreront la productivité dans cette démarche d'industrialisation de toute la chaîne de traitement : collecte, transformation, visualisations, etc.
Conclusion
En définitive, le quotidien du data scientist est un enchaînement méthodique et rigoureux d'étapes, chacune essentielle pour transformer des données brutes en solutions concrètes et éclairées. À travers la compréhension du métier et des enjeux business, le data scientist pose les bases d'un travail analytique et stratégique. L'identification et la collecte des données, suivies d'une exploration et d'une préparation soignées, permettent de créer des modèles prédictifs performants. Ces modèles sont ensuite évalués pour garantir leur fiabilité avant de passer à leur déploiement, où ils prennent toute leur valeur en répondant aux besoins réels des entreprises.
Le rôle du data scientist va bien au-delà de la simple analyse technique : il s'agit de relier des compétences mathématiques et informatiques à une vision claire des objectifs métier. En évoluant dans un environnement dynamique et complexe, le data scientist joue un rôle clé dans l'optimisation des processus décisionnels, contribuant ainsi directement à la croissance et à la compétitivité des organisations.
Certifié par


